Introduction The race to build better artificial intelligence models has fundamentally changed the way organizations think about data. In the early years of machine learning, success was often associated with dataset size. The assumption was straightforward: more data would produce better results. While large datasets remain important, the modern AI industry has learned a critical …

Introduction
The race to build better artificial intelligence models has fundamentally changed the way organizations think about data.
In the early years of machine learning, success was often associated with dataset size. The assumption was straightforward: more data would produce better results.
While large datasets remain important, the modern AI industry has learned a critical lesson:
Not all data is equally valuable.
Today, some of the world’s most advanced AI companies are investing heavily in acquiring high-quality, curated, and licensed datasets because they understand that dataset quality can have a profound impact on model performance.
A model trained on billions of low-quality data points may underperform compared to a model trained on a smaller but carefully curated collection of high-value content.
As generative AI continues to evolve, organizations are increasingly focused on acquiring datasets that improve reasoning, accuracy, reliability, and trustworthiness.
This article explores what defines a high-value dataset, why quality matters more than ever, and how AI companies can identify content that delivers long-term value.
The Shift from Big Data to Better Data
For many years, the AI industry prioritized scale above all else.
Researchers and developers focused on collecting:
- More webpages
- More documents
- More text
- More user-generated content
This strategy helped create the first generation of large language models.
However, as models became larger and more capable, a new challenge emerged.
The quality of training data began to limit performance.
Organizations discovered that larger datasets often included:
- Duplicate content
- Inaccurate information
- Spam
- Outdated material
- Poorly written text
- Low-value content
As a result, AI leaders increasingly shifted their attention from “How much data do we have?” to “How good is our data?”
Why Dataset Quality Matters
Every AI model learns patterns from the information it consumes.
If the training data contains weaknesses, those weaknesses can appear in model outputs.
Poor-quality datasets may contribute to:
- Hallucinations
- Inconsistent responses
- Factual errors
- Weak reasoning
- Biased outputs
- Reduced user trust
Conversely, high-quality datasets can help improve:
- Accuracy
- Contextual understanding
- Language fluency
- Domain expertise
- Reliability
This is why data quality has become one of the most important competitive advantages in AI development.
Characteristics of a High-Value AI Dataset
What separates a high-value dataset from an ordinary collection of content?
Several factors play a critical role.
1. High Content Quality
The foundation of any valuable dataset is quality.
High-quality content is generally:
- Well written
- Professionally edited
- Factually reliable
- Structured logically
- Easy to interpret
Content that has undergone editorial review often provides significantly more value than unverified material.
This is one reason books, educational materials, and professional publications are increasingly sought after by AI companies.
2. Rich Knowledge Density
A high-value dataset contains meaningful information rather than repetitive or superficial content.
Knowledge-dense content helps models learn:
- Concepts
- Relationships
- Reasoning patterns
- Specialized terminology
Examples include:
- Books
- Research publications
- Educational resources
- Technical manuals
- Professional journals
These sources often deliver far greater value than short-form content.
3. Long-Form Context
Generative AI systems increasingly need to understand information across extended contexts.
Books and long-form publications provide:
- Narrative continuity
- Logical progression
- Deep explanations
- Contextual relationships
These characteristics help AI systems develop stronger reasoning capabilities.
As AI agents and enterprise assistants become more common, long-context learning becomes increasingly important.
4. Diversity of Content
A valuable dataset should represent a wide range of perspectives, topics, and writing styles.
Dataset diversity may include:
- Fiction
- Non-fiction
- Educational content
- Historical works
- Business publications
- Scientific materials
Diverse datasets help reduce overfitting and improve generalization.
This enables AI systems to perform effectively across a wider range of tasks.
5. Accurate Metadata
Metadata is often overlooked, yet it plays a crucial role in dataset usability.
Useful metadata may include:
- Author information
- Publication dates
- Subject categories
- Language details
- Rights information
- Keywords
Metadata supports:
- Content filtering
- Dataset management
- Quality assurance
- Model evaluation
Well-structured metadata can significantly increase the value of a dataset.
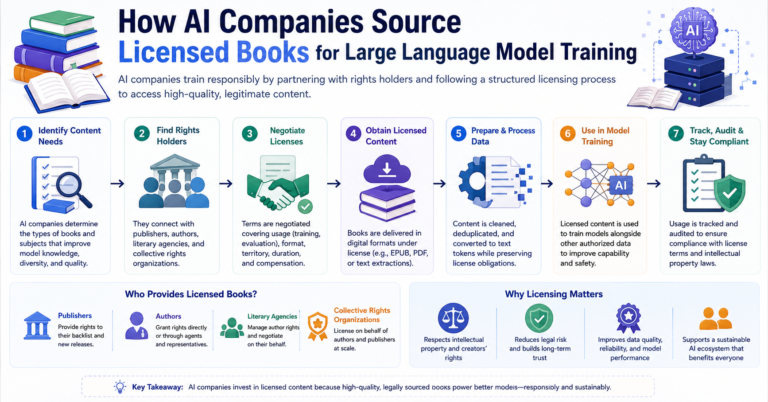
Why Licensed Content Creates Better Datasets
As AI companies seek higher-quality training data, licensed content is becoming increasingly important.
Licensed datasets often provide advantages that are difficult to achieve through uncontrolled data collection methods.
Professional Editorial Standards
Books and professionally published content usually undergo rigorous quality control.
This improves consistency and reliability.
Rights Clarity
Licensed content provides transparency regarding usage rights and permissions.
This is particularly important for commercial AI development.
Better Documentation
Professional content providers often maintain organized archives and metadata.
This makes datasets easier to manage and deploy.
Long-Term Availability
Licensing agreements can provide stable access to valuable content over time.
This supports ongoing model development and improvement.
The Importance of Domain Expertise
Many AI applications require specialized knowledge.
Enterprise AI systems may need expertise in:
- Healthcare
- Finance
- Legal services
- Education
- Engineering
- Scientific research
Generic internet content often lacks the depth required for these applications.
High-value datasets frequently include content created by subject matter experts.
This expertise helps improve model performance within specialized domains.
How High-Value Datasets Improve LLM Performance
Large Language Models benefit from high-value datasets in several ways.
Improved Accuracy
Reliable information reduces factual errors.
Better Reasoning
Long-form content helps models learn logical relationships between concepts.
Enhanced Contextual Understanding
Structured content improves the ability to maintain context over extended interactions.
Stronger Language Skills
Professionally written material exposes models to higher-quality language patterns.
Reduced Noise
Curated datasets contain fewer irrelevant or misleading examples.
This improves learning efficiency.
Enterprise AI Demands Better Data
The growing adoption of AI within enterprises is changing expectations around training data.
Businesses require AI systems that are:
- Reliable
- Transparent
- Explainable
- Consistent
- Trustworthy
These requirements place greater emphasis on dataset quality.
Enterprise buyers increasingly ask:
- Where did the data come from?
- How was it acquired?
- Can its quality be verified?
- Are usage rights clearly defined?
High-value datasets help answer these questions.
Common Mistakes in Dataset Acquisition
Many organizations still focus too heavily on scale while overlooking quality.
Common mistakes include:
Overreliance on Quantity
Large datasets are not automatically better.
Ignoring Rights Management
Unclear rights can create future challenges.
Neglecting Metadata
Poor organization reduces dataset usability.
Limited Content Diversity
Narrow datasets may weaken model performance.
Inadequate Quality Control
Insufficient filtering can introduce noise.
Avoiding these mistakes can significantly improve AI outcomes.
The Future of AI Training Data
The future of AI training is likely to be defined by quality rather than volume.
Several trends support this shift:
- Growth of enterprise AI
- Increased regulatory scrutiny
- Demand for trustworthy AI
- Expansion of content licensing markets
- Greater focus on model accuracy
As AI systems become more sophisticated, access to high-value datasets will become an increasingly important competitive advantage.
Organizations that invest in premium content today may be better positioned for future success.
Building a Dataset Strategy for Long-Term Success
AI companies should view datasets as strategic assets rather than simple inputs.
An effective dataset strategy often includes:
Curated Content
Focus on quality rather than quantity.
Licensed Materials
Establish partnerships with trusted content providers.
Diverse Sources
Include multiple content types and domains.
Strong Metadata
Maintain clear dataset organization.
Continuous Improvement
Regularly evaluate and update content collections.
This approach helps create stronger and more sustainable AI systems.
Conclusion
The next generation of generative AI will not be defined solely by model architecture or computing power.
It will also be shaped by the quality of the data used during training.
High-value datasets provide:
- Better accuracy
- Stronger reasoning
- Richer knowledge
- Greater reliability
- Improved trustworthiness
As AI companies compete to build more capable systems, access to premium content is becoming a major differentiator.
Organizations that prioritize curated, knowledge-rich, and licensed datasets are likely to gain a significant advantage in the evolving AI landscape. The future belongs not simply to those with the most data, but to those with the best data.