IntroductionArtificial intelligence is only as powerful as the data used to train it.Whether an organization is building a Large Language Model (LLM), an enterprise AI assistant, a domain-specific chatbot, or a next-generation AI agent, success depends heavily on the quality and reliability of training data.For years, web scraping was viewed as the fastest way to …

Introduction
Artificial intelligence is only as powerful as the data used to train it.
Whether an organization is building a Large Language Model (LLM), an enterprise AI assistant, a domain-specific chatbot, or a next-generation AI agent, success depends heavily on the quality and reliability of training data.
For years, web scraping was viewed as the fastest way to collect massive amounts of information. The internet offered an almost unlimited source of text, making it possible to build increasingly large datasets.
However, as AI systems become more advanced and more deeply integrated into commercial products, many organizations are reevaluating their data acquisition strategies.
Today, a growing number of AI companies are investing in licensed content rather than relying solely on scraped web data.
The reason is simple: modern AI development requires more than scale. It requires quality, transparency, compliance, and sustainability.
This article explores the differences between web scraping and content licensing, the strengths and limitations of each approach, and why licensed content is increasingly becoming the preferred choice for enterprise AI development.
Understanding Web Scraping
Web scraping is the process of automatically collecting information from publicly accessible websites.
Specialized software tools can gather large volumes of content from:
• Blogs
• News websites
• Discussion forums
• Public databases
• Educational websites
• Documentation repositories
For AI developers, web scraping provides access to enormous quantities of text that can be used for model training.
Why Web Scraping Became Popular
The early success of many AI systems was driven by the availability of large-scale internet data.
Web scraping offered several advantages:
Massive Scale
The internet contains billions of pages covering virtually every topic imaginable.
Low Acquisition Costs
Automated collection methods can gather large datasets quickly.
Broad Topic Coverage
Scraped datasets often include diverse content from multiple industries and knowledge domains.
Rapid Dataset Expansion
Organizations can continuously collect new information as it becomes available online.
These advantages helped accelerate AI development over the last decade.
The Challenges of Web Scraping
While web scraping offers scale, it also introduces significant challenges.
As AI systems mature, these limitations become increasingly important.
Data Quality Problems
The internet contains both valuable and low-quality content.
Scraped datasets often include:
• Duplicate content
• Spam pages
• Clickbait articles
• Outdated information
• Poorly written text
• AI-generated content
• Inaccurate information
Training models on unreliable content can negatively affect performance.
Many AI researchers now believe that data quality often matters more than raw dataset size.
Lack of Editorial Standards
Most web content has not undergone professional review.
Unlike books and professionally published materials, many websites lack:
• Editorial oversight
• Fact checking
• Quality assurance
• Consistent formatting
This inconsistency can create challenges during model training.
Content Volatility
Web content changes constantly.
Articles may be:
• Updated
• Deleted
• Paywalled
• Moved
• Rewritten
This makes long-term dataset management more complicated.
Rights and Compliance Concerns
One of the most significant challenges associated with web scraping is uncertainty around content usage rights.
Organizations increasingly face questions such as:
• Can scraped content be used commercially?
• What rights apply to the content?
• How should copyright be addressed?
• What obligations exist toward content creators?
These questions have become increasingly important as AI moves into enterprise environments.
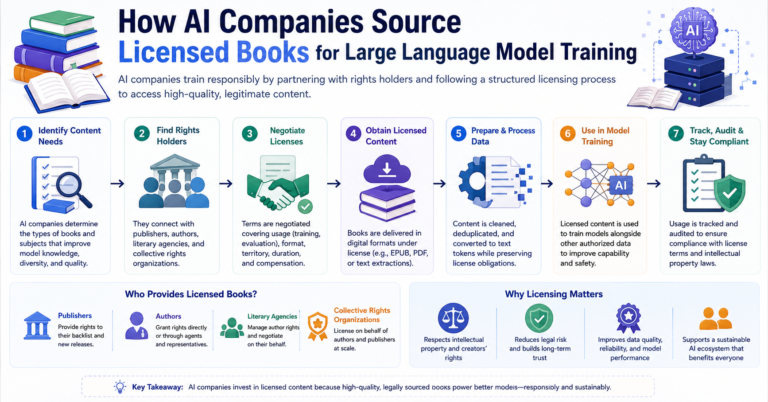
Understanding Content Licensing
Content licensing involves acquiring content through formal agreements with rights holders.
Content may be licensed from:
• Publishers
• Authors
• Literary agencies
• Educational institutions
• Research organizations
• Media companies
Instead of collecting content without direct permission, organizations establish contractual agreements that define how content can be used.
Why Content Licensing Is Growing
The AI industry is increasingly recognizing the value of licensed datasets.
Several factors are driving this trend.
Legal Clarity
Licensed content provides clear documentation regarding usage rights.
Organizations know:
• What content they are receiving
• How it may be used
• What restrictions apply
• How long access remains valid
This reduces uncertainty and supports long-term planning.
Higher Content Quality
Licensed content often includes:
• Published books
• Academic resources
• Educational materials
• Professional publications
These sources generally undergo rigorous editorial processes before publication.
As a result, they often provide more reliable training data.
Better Metadata
Professional content providers frequently supply structured metadata.
This may include:
• Author information
• Subject classifications
• Publication dates
• Rights information
• Language details
Metadata improves dataset management and model development workflows.
Comparing Web Scraping and Content Licensing
Data Quality
Web Scraping
Quality varies significantly.
Datasets often require extensive filtering and cleaning.
Content Licensing
Content is usually curated, reviewed, and professionally produced.
Advantage: Content Licensing
Compliance and Rights Management
Web Scraping
Usage rights may be unclear.
Organizations may face legal uncertainty.
Content Licensing
Rights are defined through agreements.
Organizations receive clear permissions.
Advantage: Content Licensing
Dataset Consistency
Web Scraping
Content formats and quality vary widely.
Content Licensing
Content often follows consistent editorial and formatting standards.
Advantage: Content Licensing
Speed of Acquisition
Web Scraping
Large datasets can be collected rapidly.
Content Licensing
Partnerships and agreements require time.
Advantage: Web Scraping
Long-Term Sustainability
Web Scraping
Regulatory and legal uncertainties may create future challenges.
Content Licensing
Formal agreements support long-term content access and business continuity.
Advantage: Content Licensing
Why Enterprise AI Teams Prefer Licensed Content
Enterprise AI buyers often operate under stricter requirements than research projects.
Organizations deploying AI in commercial environments must consider:
• Risk management
• Governance
• Compliance
• Data provenance
• Intellectual property
For these teams, licensed content provides a stronger foundation.
The ability to demonstrate responsible data acquisition can be important for:
• Investors
• Customers
• Regulators
• Enterprise clients
This is one reason why licensed content is becoming increasingly attractive.
The Quality Advantage of Books and Published Content
Books represent one of the strongest examples of licensed content.
Compared with typical web content, books offer:
Deep Subject Expertise
Authors often spend years developing knowledge in a specific field.
Structured Learning
Books present information in logical sequences.
Rich Context
Long-form content helps models understand relationships between concepts.
Professional Editing
Editorial review improves consistency and accuracy.
These characteristics make books particularly valuable for Large Language Model training.
The Rise of Responsible AI
Responsible AI is becoming a strategic priority across industries.
Organizations increasingly seek AI systems that are:
• Transparent
• Accountable
• Reliable
• Trustworthy
Content sourcing is an important part of this conversation.
Many companies now view content licensing as a key component of responsible AI development.
By working directly with rights holders, organizations help create a more sustainable ecosystem for creators, publishers, and AI developers alike.
Can Web Scraping and Content Licensing Coexist?
The debate is not necessarily an either-or decision.
Many organizations use hybrid strategies.
For example:
• Public web content may support broad language coverage.
• Licensed books may provide deep expertise.
• Academic publications may strengthen reasoning capabilities.
• Educational materials may improve instructional performance.
The most effective datasets often combine multiple sources.
However, licensed content is increasingly becoming the foundation upon which these broader datasets are built.
The Future of AI Data Acquisition
As AI technology continues to evolve, data acquisition strategies are evolving as well.
The industry is moving toward:
• Higher-quality datasets
• Better governance
• Greater transparency
• Improved compliance
• Stronger publisher relationships
Organizations that invest in trusted content sources today may gain significant competitive advantages in the future.
The next generation of AI systems will likely depend not only on the quantity of data available but also on the quality and legitimacy of that data.
Conclusion
Web scraping played a critical role in the development of modern artificial intelligence.
It enabled rapid experimentation and access to vast amounts of information.
However, as AI systems become more sophisticated and commercially important, organizations are recognizing the limitations of relying exclusively on scraped content.
Licensed content offers clear advantages in terms of quality, consistency, rights management, transparency, and long-term sustainability.
While web scraping will likely remain part of the AI ecosystem, content licensing is increasingly emerging as the preferred approach for organizations building reliable, enterprise-grade AI systems.
For companies seeking trustworthy training data and long-term scalability, licensed content is becoming a strategic investment rather than simply a compliance consideration.
About Bookscape
Bookscape connects AI companies with high-quality, rights-cleared books and publishing content for Large Language Model training, generative AI systems, AI agents, enterprise copilots, and knowledge platforms.
We help AI developers access professionally curated content through transparent and scalable licensing partnerships.